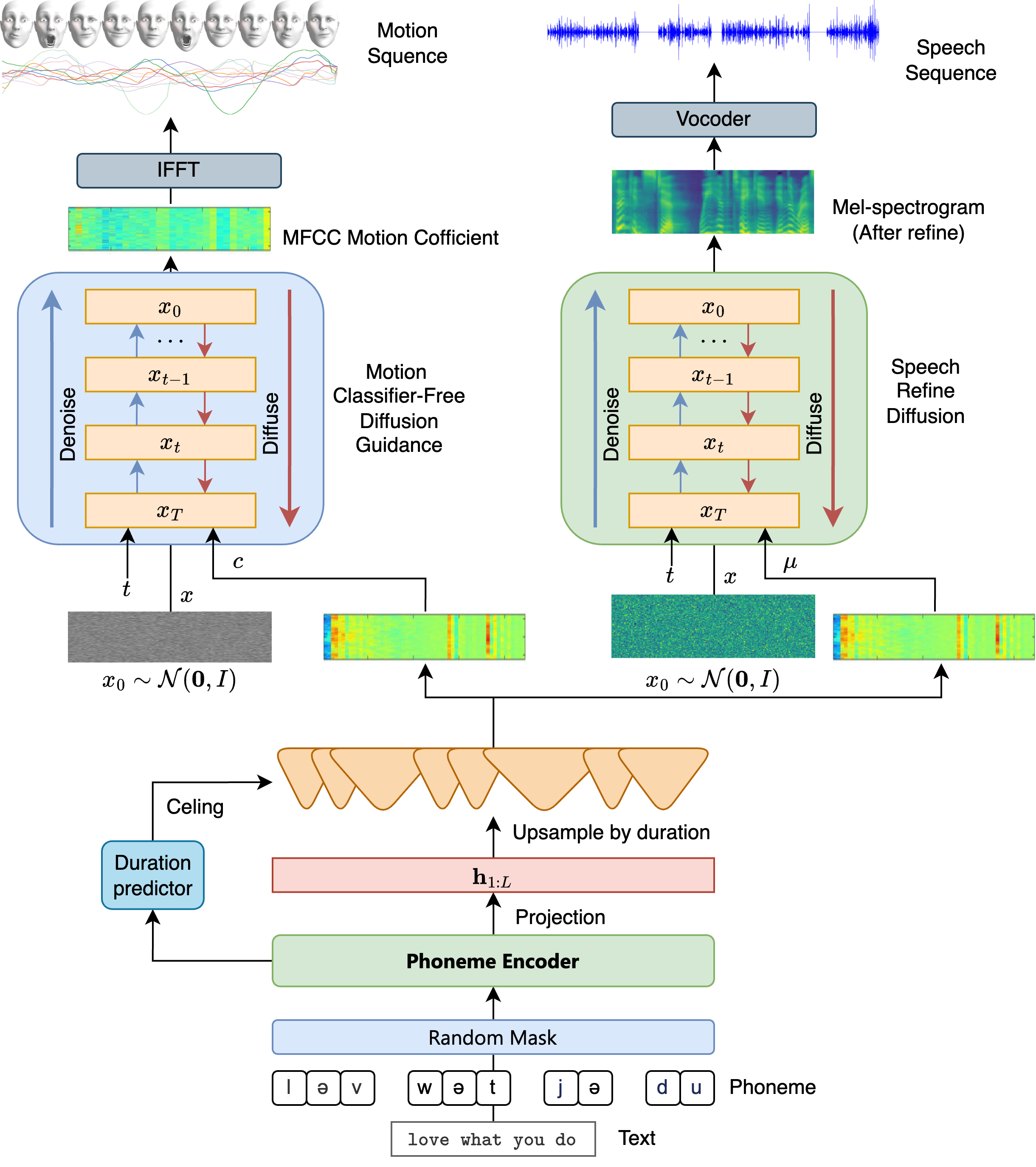
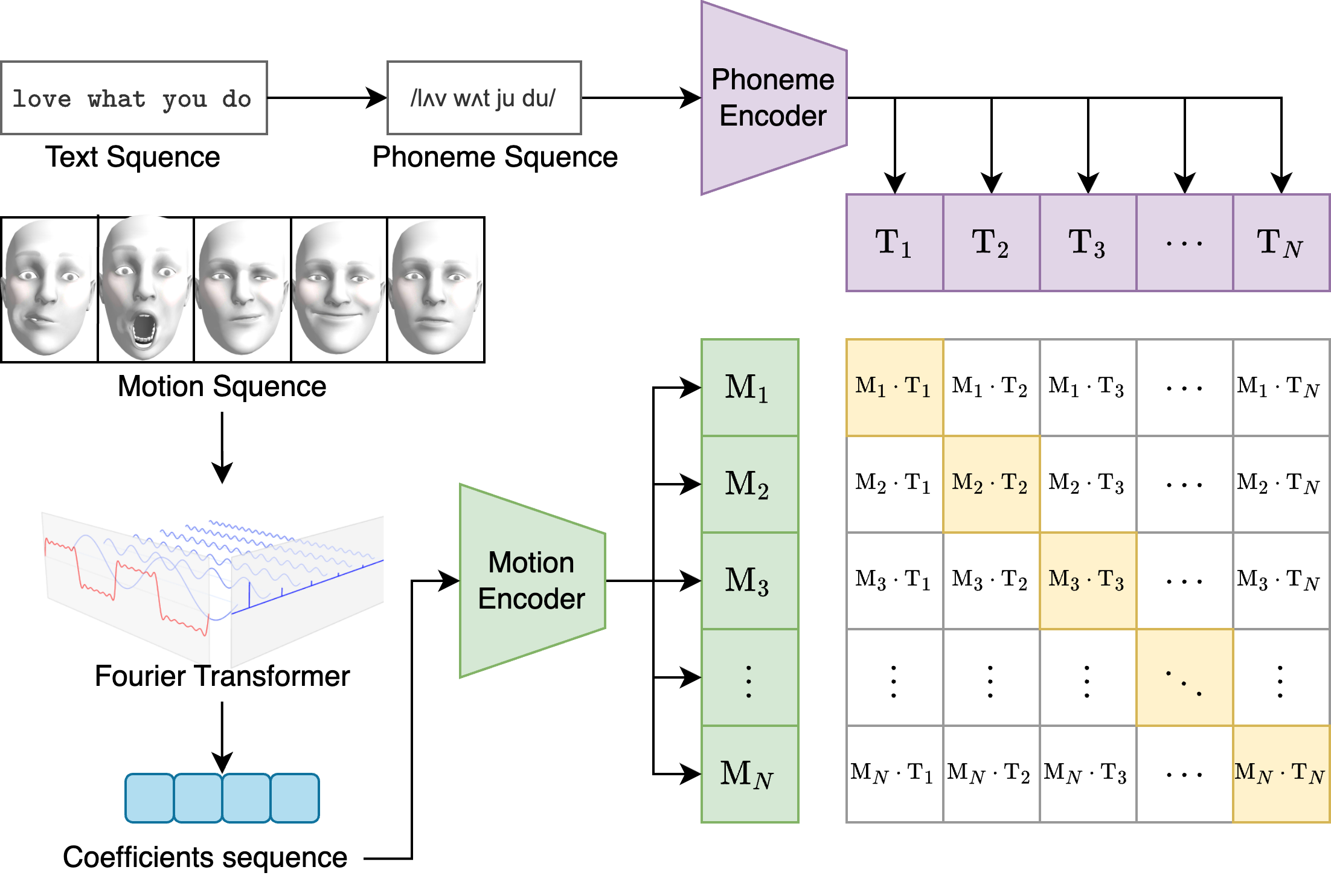
Recent text-to-speech (TTS) systems have achieved high fidelity, but often rely on supervised learning paradigms that require extensive labeled data and struggle to generalize to diverse, unseen speakers. We present PhaseSpeech, a novel TTS framework that leverages self-supervised learning to create highly personalized and natural speech without relying on manually annotated prosody labels. Our core innovation is a two-stage pipeline that decouples the problems of content representation and speech generation. First, we introduce a Voice-Print CLIP (VP-CLIP) model that learns a joint embedding space between phonemes and mel-spectrogram segments via masked contrastive learning, conditioned on a speaker embedding. This allows for speaker-specific, context-aware retrieval of audio segments directly from a phoneme sequence. Second, a lightweight flow-matching refiner, conditioned on the same speaker identity, denoises and enhances the concatenated retrieved segments to produce final, high-quality mel-spectrograms with seamless transitions and natural prosody.
By separating retrieval from refinement, PhaseSpeech achieves significant gains in inference speed and production efficiency, as the retrieval step can be heavily optimized through caching. Furthermore, the self-supervised nature of the contrastive learning objective allows the model to learn nuanced prosodic features like rhythm and intonation directly from raw audio, eliminating the need for costly prosodic labeling. Evaluations on benchmark datasets demonstrate that PhaseSpeech outperforms state-of-the-art TTS systems in both subjective naturalness and speaker similarity, while also being significantly more efficient and adaptable to new voices with minimal data.